
西安交大一附院信息中心主任、普通外科教授 樊林
现代医学发展日新月异,她正经历一场重要的变革,其核心的动力来自于组学技术、计算技术、靶向药物及基因编辑等技术的快速发展。新的疾病预防及诊疗模式中需要涵盖临床数据、多种组学数据、环境暴露、日常生活习惯、地理位置信息、社交媒体及其他多种与个体健康和疾病状态相关的数据维度,提供高度个体化的预防及诊疗方案。目前,借助上述维度的医学大数据的研究已经得出了诸多重要成果,包括群体层面的疾病预防及诊疗体系的评价、特定疾病的机制阐释以及个体患者的疾病诊疗决策支持。
医院的信息管理部门需要转变思想,亟需紧跟医学模式的变革及技术发展的潮流,改变单纯的IT技术服务及流程改造,在“数据→信息→知识→行动”这一过程中积极进行有益的尝试,推动临床、科研及产业界的联动,推进医学大数据为中国的公共卫生、临床医学及基础医学的进步发挥作用。而依托综合性大学的计算科学实力、医学院校的基础医学研究、医院系统的临床病例资源及产业界的创新技术是理想的合作模式,这方面西安交大一附院正与西安交大之间进行积极的探索,希望能为在数据共享、科研平台构建、新技术探索、成果转化及临床服务方面逐步积累经验,构建领先的精准医学临床及科研平台。
大数据(Big Data)在基础医学、临床医学及公共卫生领域的应用正如火如荼。随着二代、三代测序技术的突飞猛进,人类对于基础的分子生物学规律的认识日渐加深,对于人类疾病与健康的认识也逐步产生革命性的变化。全基因组、全外显子组、转录组、蛋白质组、DNA甲基化、微生物组等一系列组学数据即将成为临床诊断与治疗的重要依据。这些组学数据的基本特点是数据量庞大、结构复杂、分析难度大。医学大数据的广泛应用是实现传统医学模式向“精准医学”(Precision Medicine)转变的必要前提和核心动力。
精准医学即充分考量患者在基因、环境及生活方式中存在的个体差异以达成最有效的疾病治疗和预防的医学模式,其核心理念是将与人体健康及疾病预防相关的多个维度的数据进行统合。其中不仅包括临床数据和基因组数据,也包括环境暴露、日常生活习惯、地理位置信息、社交媒体及其他多种多样的数据。我们可以对人体的疾病状态和发展过程进行更相近的描绘和更为透彻的理解。医学大数据为生物学家、临床医生、流行病学家及医疗卫生政策制定专家提供了有效的工具,使得数据驱动的决策制定成为可能,并最终对患者及整个人群产生有益影响。
近期的影响深远的研究指出了医学大数据的重要应用方向:群体层面的疾病预防及诊疗体系的评价、特定疾病的机制阐释以及个体患者的疾病诊疗决策支持。基于对最新的科研进展的分析,本文就医学大数据的主要应用方向进行阐述。
医学大数据的定义及特性
大数据(Big Data)是指数据量庞大、数据结构复杂且依靠传统的方法和工具难于处理的数据集。处理这个词包含了数据获取、存储、格式化、抽取、curation、整合、分析及可视化等。大数据的通用定义是“3V”模式定义,由Gartner提出,指出了大数据的三个核心特征:数据量庞大、数据流高速及数据类型极其丰富。
生命科学领域所涉及的大数据与经济、社交媒体、环境科学等领域的大数据存在明显不同。通过对目前已发表的关于医学大数据的定义(包括Biomedical Big Data, Big Healthcare Data等词条),Baro, E.等对医学大数据提出了如下的定义模式,并将数据量作为最核心的定义指标。这在一定程度上反映了目前学术界对于医学大数据的认识,定义体系值得进一步商榷,但其提取的文献中对于医学大数据特征的认识与通用的大数据的概念相吻合,也具有生物医学领域的独特之处。

医学大数据对群体层面的疾病预防及诊疗的意义
大数据在医学和临床研究中意义重大,主要的研究中心和科研经费发放机构已经在这方面进行了大量的投入。例如,NIH近期投入了1亿美金用以将11个数据库整合为BD2K(Big Data to Knowledge Initiative)项目,致力于广泛整合数据源并构建开放型转化医学应用平台。最有名的此类医学大数据库当属Medicare and Healthcare Cost and utilization Project,其中包含超过1亿条记录。在这样的数据规模的基础上,对于群体层面的疾病预防和诊疗体系的评价成为可能。
临床大数据的主要应用之一是分析某一疾病或表型在不同人群中的患病率及发病趋势,其中,传染性疾病的监测是医学大数据技术应用最成功的的场景之一。基于Google的检索数据进行的流感病毒预测是全球公共卫生界每年关注的重大议题,对流感疫苗的研发、高危人群的接种、重症流感风险的预测等具有重要的意义。2014年,对Ebola病毒流行的预警及流行趋势分析让各国政府对使用医学大数据进行数字化的疾病流行监控给予更多的关注。在发生Ebola病毒大流行之后,来自发病地区的检索次数急剧增加,且检索来源最多的地区正是病毒流行最为严重的地区。从图1中可以看出,Google搜索指数与报告病例数呈正相关。对每周报告病例数与“ebola”这个词条的检索频率进行Spearman检验,在三个国家的相关性分别为几内亚 0.54,利比亚0.7,塞拉利昂0.68 (所有p值均低于0.001)。
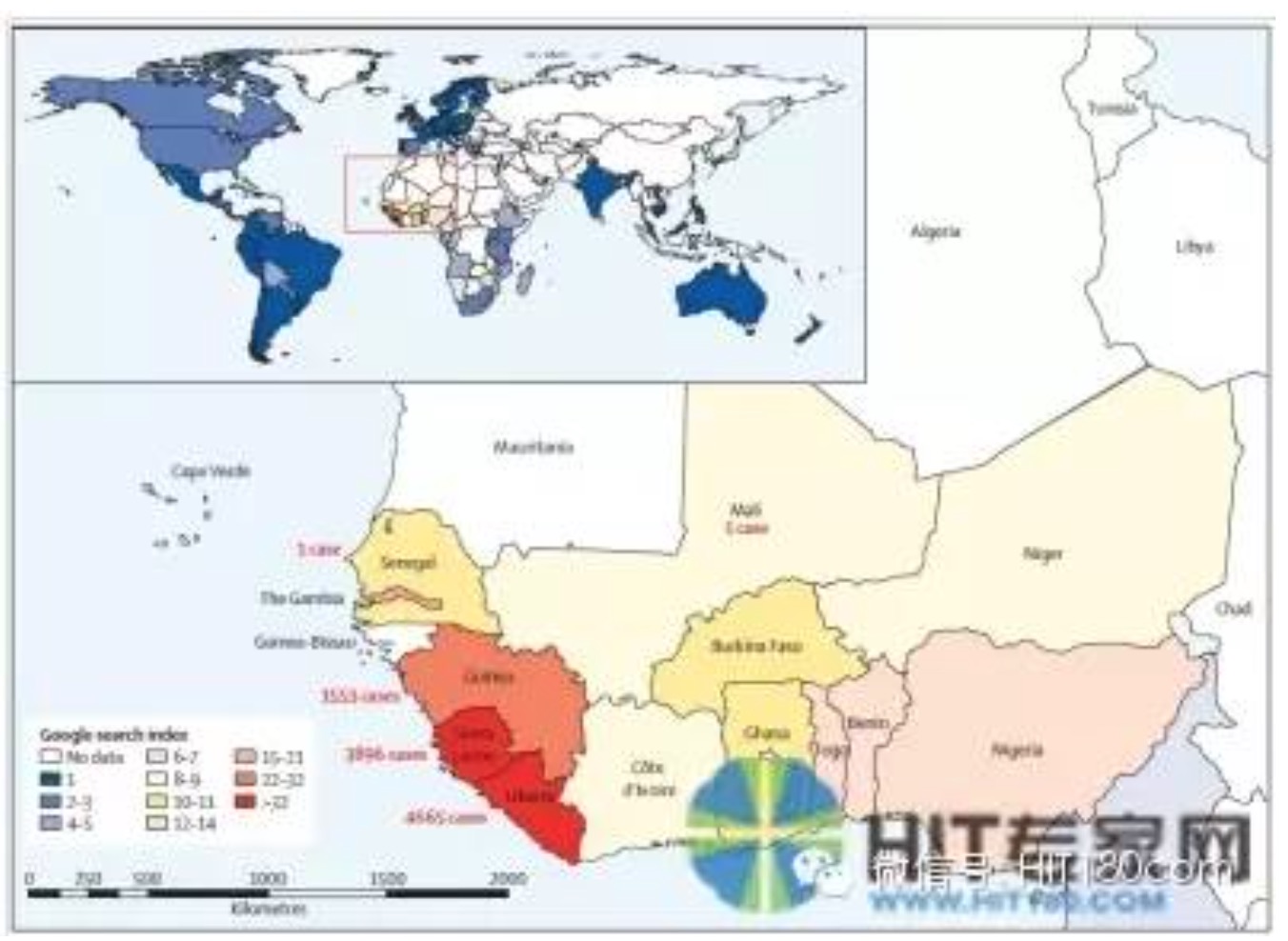
图1:2014年词条“ebola”检索的地理分布 (图片引用自:The Lancet Infectious diseases 2014;14:160-8.)
临床大数据也可用于研究危险因素与疾病之间的因果关系、效应或相关性。Ursum等在18658例类风湿关节炎患者中分析血清转换和年龄与自身抗体的炎症效应。该研究表明抗环瓜氨酸肽抗体比类风湿因子对于类风湿关节炎的评估更为可靠。From等对35922例患者中进行的53177次造影剂使用进行分析发现使用了碳酸氢钠制剂的患者出现造影剂肾病的风险增加。Mitchel等在英国的800万糖尿病患者中筛选出7720例患者用以分析两种类型胰岛素的作用。Kobayashi等分析了来自3500家日本医院的19070份右半结肠切除术的电子病历,并成功开发了一个风险预测模型。值得注意的是在这些研究中,“相关性”和“因果关系”这两个术语必须严格厘清范畴。大部分的研究只能论证相关性,而很难直接证实因果关系。
大数据技术可以在宏观层面得出规律,对重大决策进行支持,这在社交媒体、公共安全、交通等方面已有大量应用。在医学大数据领域,这样的应用也具有其独特的意义。近期公布的一项研究对美国2001年至2011年间近8000万份出院电子病历信息进行分析,评估美国住院患者中超声心动图的使用情况(如图2示)。尽管在这项研究结果发布之前,学术界存在“超声心动图被滥用”的观点。这项研究的结果却证实:在大量的因为心血管重症入院的患者中,超声心动图并没有得到有效的应用5。这样的结果可以为临床诊疗质量改进、慢性病管理指标体系构建、医保付费政策的调整、医生继续教育等提供重要的决策支持,并进而通过改变相应的临床诊疗流程为患者带来获益。
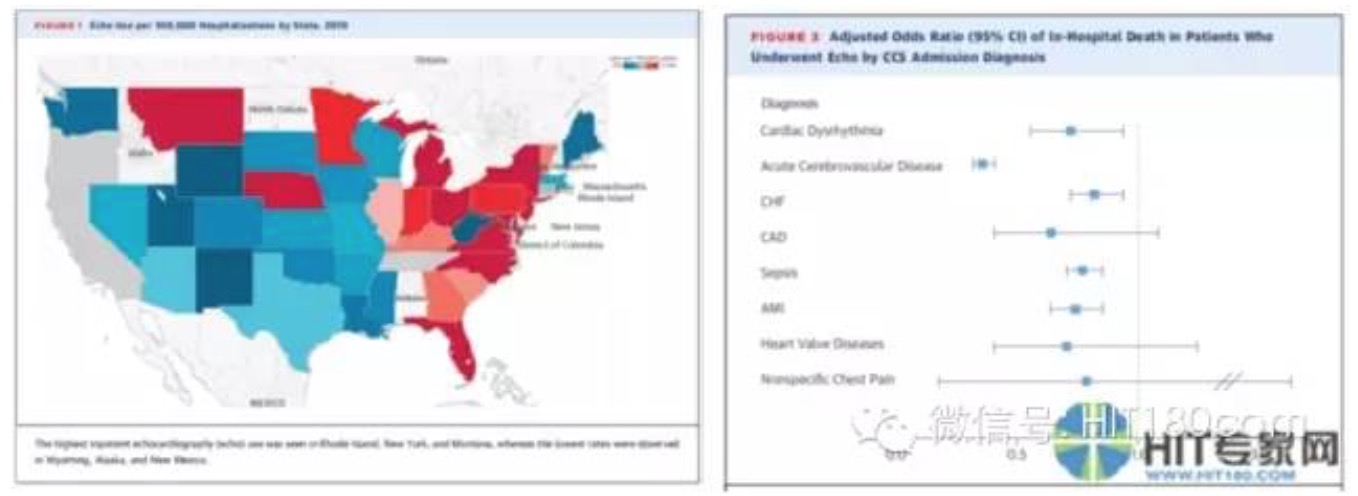
图2:(左)美国住院患者接受超声心动图检查的情况 (频率最高的地区分别为罗德岛、纽约及蒙大拿;频率最低的地区为怀俄明、阿拉斯加和新墨西哥)。(右):接受超声心动检查的患者的住院死亡风险低于不接受超声心动检查者。(图片引用自:Journal of the American College of Cardiology 2016;67:502-11.)
医学大数据为特殊疾病的机制阐释提供有力支持
人类对疾病机制的阐释长期以来受到样本量不足、混杂因素过多、随访体系不完善等困扰。医学大数据技术在这些方面具有显著的优势,因而受到学术界越来越多的青睐。近期发表的一项重要研究中,研究人员对16025例朊粒疾病(Prion Disease,罕见病,发病率约2/100万人年)患者的外显子组、60706例对照人群的外显子组和531575例23andMe(基因测序服务公司)测序个体的外显子组数据进行分析,得出了这一极为罕见的疾病的63个已报到的突变位点的外显率(即致病可能性)。之前认为携带这些突变的个体几乎无一例外地会在40-50岁之间死于神经退行性疾病。该研究首次证实某些突变位点的致病可能性极低,为携带这些突变的患者解除了“死亡宣判”。这项研究所借助的数据库之一为ExAC(Exome Aggregation Consortium)。这是一个由多个国家的科研机构组成的外显子组测序数据共享平台,内含6万余份无亲缘关系的个体的外显子组测序信息。考虑到每一份全外显子组测序的数据所包含的庞大的信息量,处理这些数据对于计算技术也提出了巨大的挑战。基于这些数据,医学界首次有机会将人群中与种族起源密切相关的基因变异(Variants)与临床疾病之间的关系逐步进行阐释,为未来利用基因组数据指导疾病的诊断和治疗奠定基础。
随着基因型分析技术的进步,大量的研究出现在基因表达的分析及基因组数据的信息在病例与对照组之间的差异。例如,使用华法令治疗的5700例患者的临床和基因信息被用于分析并建立了预测合理剂量的算法。Koefoed等尝试分析803个单核酸多态性(SNP, Single-nucleotide Polymorphism)中任意3个的组合对信号传导的影响,共有约23亿个组合形式,分析群体为双向情感障碍,包括1355个对照组病例和607组病例。这些研究与危险因素研究类似,但在遗传分析领域使用的数据集的体量通常远超过危险因素研究的数据集。ACCENT研究利用来自25个结肠癌辅助化疗临床试验的37568份病历资料进行分析,对发病率不到2%的早发死亡的风险因素进行了评估。因为出现的频率较低,早发死亡在传统的研究体系下无法明确其原因。ACCENT研究所构建的医学大数据成为寻找此类罕见但意义重大的临床情况发生原因的重要工具,并为相关性假设提供足够的统计学分析效力。
医学大数据在个体患者的诊疗决策支持发挥关键作用
个体化医学(Personalized Medicine)的概念由来已久,在医学界得到广泛的认可。将基因组数据等医学大数据应用于临床诊疗是将个体化医学提升至精准医学的必由之路,其中包括两个至关重要的步骤。
1.对医学大数据进行数据挖掘,以逐步完善精准医学的知识体系。
对医学大数据进行挖掘以产生新的知识是目前各类组学研究的重点,目前存在于公共数据平台的海量的医学大数据是进行研究创新的绝佳资源,包括基因组、转录组、蛋白质组及表观基因组学数据等。NCBI Gene ex pression Omnibus (GEO) 数据库就是其中之一,包含来自3万多个研究系列的100余万份人体肿瘤组织基因表达数据(基于基因芯片技术)。其他重要的组学信息共享平台还包括1000 Genomes项目、DNA组件百科全书(ENCODE)项目和肿瘤基因组图谱(TCGA)项目等。
2015年发表于关于PRAP抑制剂Olaparib治疗终末期前列腺癌的研究引起了学术界对于根据肿瘤基因组学检测数据对疾病进行分子分型的临床意义产生了全新的认识27。研究者对49例晚期且存在全身广泛转移的前列腺癌患者的肿瘤组织进行基因测序,并根据与DNA修复相关的基因(包括BRCA1/2、ATM、Fanconi贫血基因和CHEK2)进行分型。结果显示:如其肿瘤组织存在上述基因的等位基因同源缺失和/或功能缺失性突变,88%对PRAP抑制剂治疗有效。如无上述突变,有效率则仅为6%。鉴于与DNA修复相关基因的重要临床意义,需要明确人体肿瘤组织可能出现的所有类型的变异(包括位点变异和拷贝数变异)及其是否会导致基因转录、表达等相应下游改变,从而为用药提供指导。Fehrrmann等利用GEO数据库中约10%的数据对肿瘤组织中所有已经检测到的与DNA修复相关的基因拷贝数变异进行分析。研究人员对其中的近8万份表达谱数据进行深度挖掘,使用主因素分析(Principal Component Analysis, PCA)的方法从中找出一定数量的生物学功能已知的转录因素,用于解释基因表达谱中存在的绝大部分差异。在此基础上,研究者构建了一个包含19997个基因的模型,以此来预测其中某些基因的生物学功能。使用这些转录组分对表达谱进行修正后,研究者观察到残余表达水平(功能基因组mRNA谱, FMP)与拷贝数呈强相关。DNA拷贝数与99%的丰量表达的人类基因的表达水平相关,这表明了global基因剂量敏感性。使用这个方法,研究者分析了近12万份人类肿瘤组织标本,从中确认了大量的出现拷贝数变异的位点以及在那些基因不稳定的肿瘤中反复出现的被破坏的基因。作者在研究中证实了基因组不稳定性的程度与卵巢癌患者的生存之间存在相关性。他们发现的与基因组不稳定性相关的基因可以被用于预测肿瘤对于某些以损伤DNA为主要机制的化疗药物的敏感性,并可能最终帮助发现新的治疗方案。
2.基于大数据构建具有自主学习能力的临床决策支持系统。
受限于样本量、抽样偏倚、环境差异等影响,在宏观层面从医学大数据中挖掘提取出的知识应用于个体化诊疗必然会伴随着可能的误诊误治。解决医学大数据的个体化应用的核心技术难点在于利用机器学习和临床决策支持系统(Clinical Decision Support System, CDSS),将多个维度的数据进行整合,为医生和患者提供精细化、个体化的诊疗指导。
以哮喘为例,大量的证据证实不同的哮喘患者的临床表现存在显著的异质性。这种个体差异体现在发病年龄、性别、与肥胖的关系、气道高反应性的严重程度以及对于不同药物的治疗反应等各个方面。哮喘其实是一组疾病的集合,其中每个亚型均由不同的生物网络所驱动,具有独特且互相重叠的基因组、转录组、炎症因子谱、生理学及临床表现。传统的血液、痰液生化指标及最新的血液、痰液基因组学及转录组学研究可以对同样诊断为哮喘的患者进行进一步的亚群分组,从而选择出最佳的治疗方案7。结合患者的人口学数据、诊断、基线肺功能评估结果、既往用药、基因组分析及痰液转录组分析制定初步方案;利用可穿戴设备(便携式峰流速仪),收集患者每日的峰流速(重要的反馈指标),结合当日用药剂量及种类、环境中花粉监测数据、PM2.5数据、流感病毒流行数据等,使用人工神经网络构建机器学习模型,逐步修正参数,最终优选出最重要的指标及参数,实现自动计算当日用药的功能,目标是最大程度地控制急性哮喘发作,减少急诊入院,并在长期改善患者心肺功能。这在各类肿瘤及高血压、糖尿病、抑郁症等各类非肿瘤性慢性疾病的诊治过程中均具有极为广阔的应用前景。
【结语】
医学大数据的发展目前面临一系列障碍,包括技术的限制、成本高昂、处理及分析数据对于多学科知识的要求等。医学大数据的应用需要经历“数据→信息→知识→行动”的过程。构建标准并基于战略互操作性(Strategic Interoperability)及隐私管理规范进行数据共享是进一步增大数据量的重要手段;计算科学、机器学习领域的进步是从数据中提取知识的关键动力;与临床信息进行深度整合、在真实世界证据(Real-world evidence)及统计学体系的支持下产生新的知识是医学大数据应用的主要方向;而使用这样的知识改变疾病的诊疗体系,提升人类健康则需要政策法规、医学伦理、医生及患者教育、制药和IT等产业界共同参与等一系列要件。
中国在医学大数据的应用上面临诸多困境,最重要的是目前在政策法规、伦理研究、安全技术等数据共享的顶层设计方面准备不足,医院内部和医院之间信息孤岛林立,科研机构间的数据共享名存实亡。尽管我们在基因测序技术、计算科学及机器学习方面有一定的优势,缺乏临床数据体系的检验,这些数据难以产生信息和知识,更谈不上应用和行动。科技部近期发布的关于精准医学的科技专项中,已将上述顶层设计中的缺陷列入重点支持的内容,以构建良好的医学大数据应用生态系统。相信政策导向可以带动学术界、医疗行业及产业界联动,共同推进医学大数据为中国的公共卫生、临床医学及基础医学的进步发挥作用,增进人民的福祉。
(致谢!阿里巴巴公司技术专家袁泉和龙海涛对本文在大数据技术专业领域的内容提出了宝贵意见。)
弓孟春,InterSystems临床顾问。
陆亮,西安交通大学附属第一附属医院网络信息中心。
特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。
医学科研干货免费下载,请搜索“肽度时界”公众号,关注后回复“指定数字”获取:
1.【测序大数据】2016年全球二代基因测序行业投研报告 --回复“006”领取
2.lncRNA超级干货(68篇文献免费阅读) --回复“007“领取
3.SCI论文超级干货合集(SCI论文写作技巧+配图软件+施一公大咖经验+文献检索+SCI经验书籍) --回复“008” 领取
4.【PDF报告】中国移动医疗市场年度研究报告2016 --回复“009”领取返回搜狐,查看更多
责任编辑: